01.03.2011 [17:45], Андрей Крупин
Спустя восемь месяцев после включения в состав Google Docs механизма оптического распознавания текста из PDF-файлов или изображений форматов JPG, GIF, PNG, разработчики онлайнового офисного пакета сообщили о расширении списка поддерживаемых OCR-системой языков. Теперь алгоритмы последней обеспечивают распознавание текстов на 34 языках, включая русский.
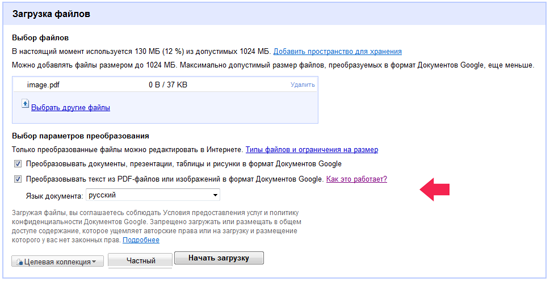
Элементы управления OCR-модулем расположены на странице загрузки файлов в Google Docs. Достаточно выставить галочку напротив опции "Преобразовывать текст из PDF-файлов или изображений в формат документов Google", и система автоматически извлечет из отсканированных документов и цифровых фотографий текстовые данные для их последующей правки в текстовом редакторе.
Вся статья на 3dnews.ru

0 коммент.:
Отправить комментарий